


Crawling through Umbraco with Sitemaps

Websites come in all shapes and sizes. Some are fast, some are beautiful, and some are a complete mess. Whether it's a high-quality site is irrelevant if people can’t find it, but search engines are here to help. Though the competition to get on first page is tough, this series will dive into some common practices to make your website crawlable.
Series:
- Crawling through Umbraco with Sitemaps (this one 😎)
- Crawling through Umbraco with Robots
What is a Sitemap? #
Sitemaps are a tool to facilitate search engines to crawl your website. At its core, a sitemap is a simple XML file listing all pages you want to be indexed by search engines. When a crawler visits your homepage, it will index that page + look for all the links it can follow to other pages. The crawler may not find all your pages using this method. So sitemaps will help search engines crawl your site and find those harder to find pages. It’s a very common tool that goes back to 2005 when it was introduced by Google and is still being used to this day.
Example:
These are some great resources for more information on sitemaps:
- https://en.wikipedia.org/wiki/Sitemaps
- https://www.sitemaps.org/protocol.html
- https://support.google.com/webmasters/answer/156184?hl=en
Sitemap implementation in Umbraco #
As mentioned above, a sitemap is ultimately a simple XML file listing out all pages for search engines to crawl. But how do we go about generating this xml file in Umbraco?
There are a few things to consider before heading into the code:
- Umbraco’s content tree is by nature a nestable structure, while a sitemap XML is a flat list where nesting isn’t allowed.
- At a minimum, a Sitemap needs to know the Location (URL) and Last Modified Date for a page, though there are two optional pieces: Change Frequency and Priority.
- Not all content in Umbraco is a page, but only pages should be listed in sitemaps.
- Websites usually have some pages that shouldn’t be indexed.
This translates into the following requirements:
- Content Items representing a page need to be distinguishable from non-page content items.
- Page Content Items nested structure needs to be flattened.
- Specific Page content items can opt out of being in the Sitemap.
- Specific Page content items need to hold data for Change Frequency and Priority. Location and Last Modified are build in properties that every Content Item has.
Adding a BasePage composition #
We’re going to start from a fresh Umbraco installation (version 7.12) and use the ContentModel `live` mode which is the default.
To be able to distinguish non-Page Content Items from Page Content Items, we’ll introduce a `Base Page` composition which all Page Document Types have to inherit from.
Add the following configuration to your Base Page Composition:
- Crawling (tab)
- Exclude From Sitemap
- Type: Checkbox (True/False)
- Alias: sitemapExclude
- Sitemap Change Frequency
- Type: Custom Editor Dropdown
- Alias: sitemapChangeFrequency
- Prevalues:
- Always
- Hourly
- Daily
- Weekly
- Monthly
- Yearly
- Never
- Sitemap Priority
- Type: Custom Editor Decimal
- Alias: sitemapPriority
- Configuration:
- Minimum: 0
- Step Size: 0.1
- Maximum: 1
- Exclude From Sitemap
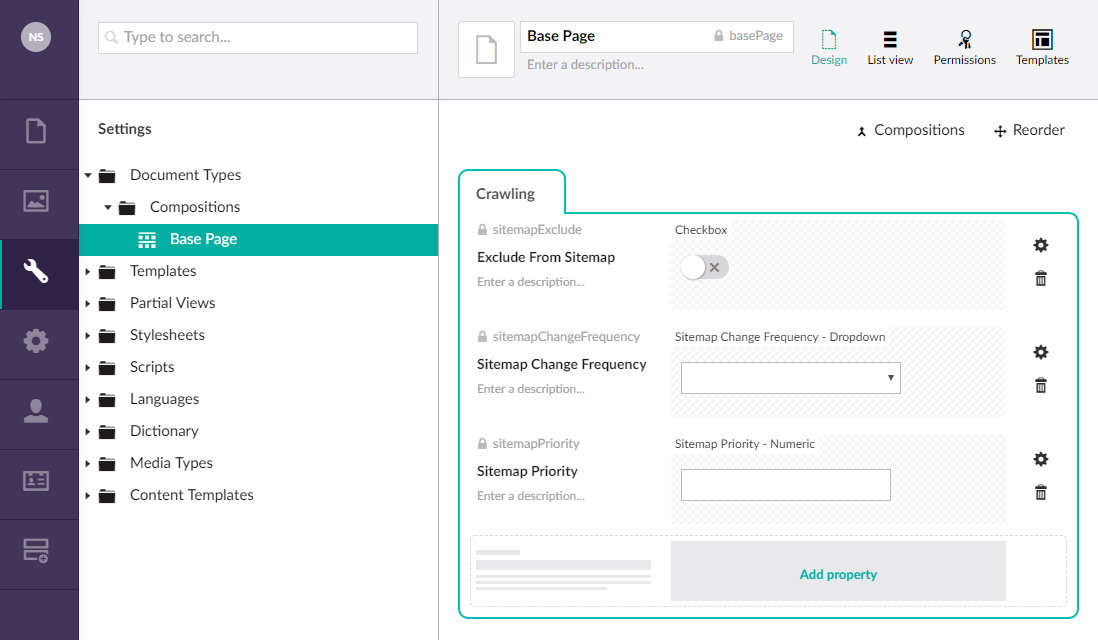
We have our composition in place, but we don’t have any page document types yet. Let’s create two page document types with templates:
- Home Page
- Allow Generic Page under Home Page
- Allow Home Page at root
- Generic Page
- Allow Generic Page under Generic Page
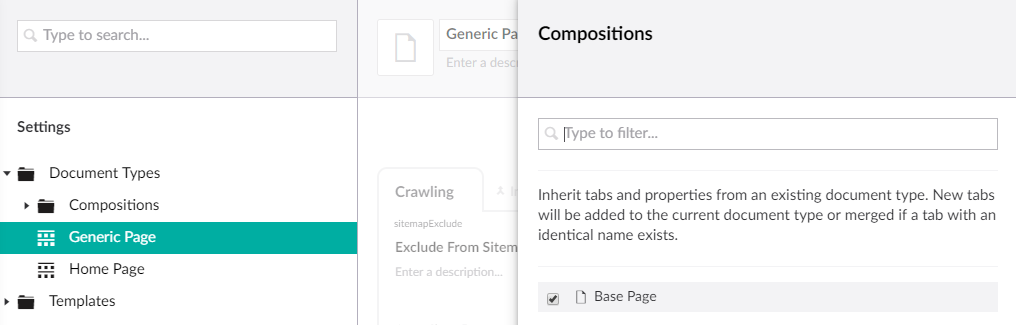
Let’s keep the templates for these pages very simple, like below:
GenericPage.cshtml
HomePage.cshtml
Now that the Document Types are ready, let’s create some content! Below is a screenshot of the content I created.
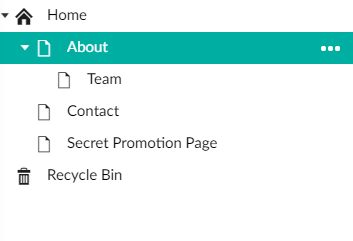
the pages need to show up in the Sitemap except for our “Secret Promotion Page”, so make sure to check “Exclude From Sitemap” toggle.
Generating the Sitemap file #
We’re halfway there, we have our data and structure ready to pull into the Sitemap. In order to generate the Sitemap, we need to create one more Document Type with template. This time the Document Type will be completely empty since we don’t need any properties, but we do need to allow the creation of the Sitemap Document Type under the Home Page. Let’s add a Sitemap content item under the homepage called ‘sitemap’.
It’s finally time to write some code! Add the following Razor code to the Sitemap template.
First we set the Document Type of the HTTP response to ‘application/xml’ because we’re returning XML instead of HTML. After that we an XPath query, to query all content that has a `sitemapExclude` property set to false (0).
Once we have the pages, we iterate over each page and print out the URL, UpdateDate, sitemapChangeFrequency, and sitemapPriority.
When visiting our sitemap content item, the server returns our brand-new sitemap.
Setting up a rewrite rule to /sitemap.xml #
Search Engines do not require the sitemap file to be called ‘sitemap’ or ‘sitemap.xml’, nor do they require the sitemap to be at the root of your domain. Though, most commonly you can find the sitemap of a site by browsing `/sitemap.xml`, so let’s comply to this unwritten standard.
Out of the box, Umbraco doesn’t allow you to add a file extension to your content item. If we’d rename our ‘sitemap’ content item to ‘sitemap.xml’, the URL Umbraco generates is `/sitemapxml` (if you renamed the content item to ‘sitemap.xml’, rename it back to ‘sitemap’).
As with anything there’s many solutions to a given problem. For a sitemap, the simplest solution is to use a simple IIS rewrite.
Add the following rewrite configuration to your web.config file:
Both `/sitemap.xml` and `/sitemap` now return our new Sitemap.
What the hack, Google says the Sitemap URL's are duplicate content!? #
When you submit your sitemap to Google, you may notice after a while that Google actually "Excluded" many of the URL's in your sitemap.
You can check this in the Google Webmaster console, under the Coverage report.
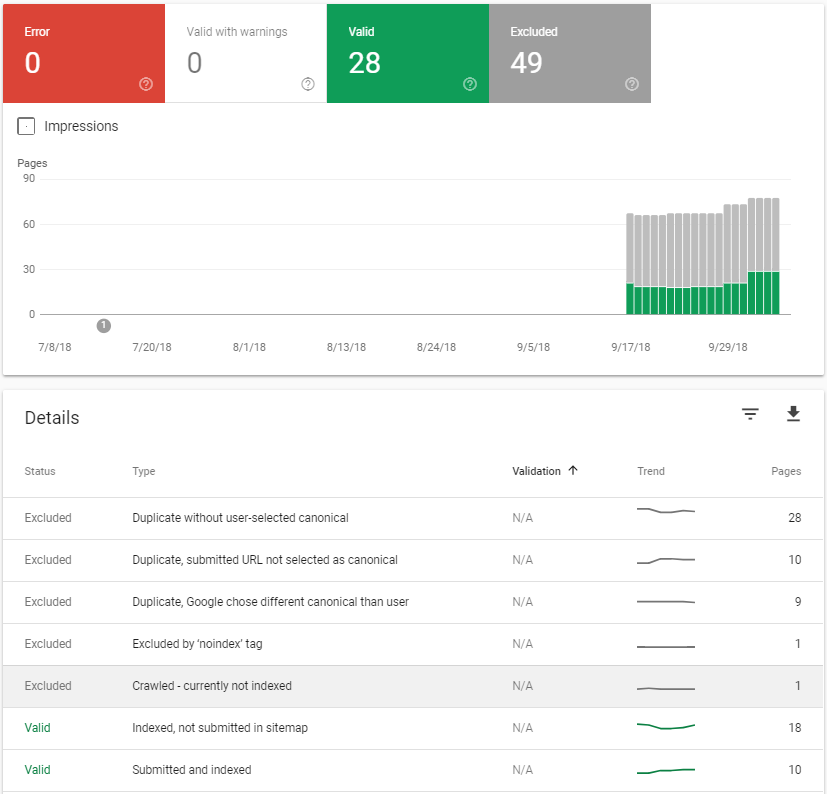
There are many possible reasons for certain URL's to be excluded, but there's one reason in particular that I want to draw your attention to.
Google see's that the following URL's all return the same content, and picks only one of these URL's to show in Google Search.
- https://www.contoso.com/about-us
- https://www.contoso.com/about-us/
- https://www.contoso.com/ABOUT-US
The reason Google reports these different URL's is because somewhere in your website you appended '/', and somewhere else you omitted the '/'.
These kind of inconsistencies will cause both URL's to show up in Google Webmaster tools and it will be marked as duplicate content.
Here's some more information from Google on this issue and how to address it.
Here's some suggestions to fix this problem:
- Choose to enforce URL's with or without appending a slash
- Choose to enforce URL's that are all lowercase
- Keep your URL's consistent everywhere (sitemaps, HTML, outside links)
- Enforce consistency by setting up redirects when incoming request URL is not following enforced rules
To slash or not to slash #
In Umbraco there's a setting that will always append, or always omit a trailing slash when using Umbraco's API to generate URL's.
This setting is called `addTrailingSlash` which can either be set to true or false. The choice is up to you, Google doesn't prefer any over the other, but it does care about consistency!
By default, Umbraco generates URL's that are always lowercase, but maybe you have some custom code that generates URL's.
Make sure you follow the same fashion, unless you require different casing for some reason. If you do require different casing in some parts of your website, make sure IIS redirects do not affect those.
Redirect inconsistent URL's #
There are two redirects you can use to enforce consistency: one for trailing slashes, and one for lowercase URL's.
If you want to enforce no trailing slashes, use the following redirect:
If you want to enforce a traling slash, use this one:
If you want to enforce lower case URL's, use this redirect rule:
Now that Google sees these redirects, the amount of duplicate content should decrease. Search Engines will better understand that all the forementioned URL's are one and the same page.
How will other Search Engines find my sitemap? #
Both in Bing (+ Yahoo) and Google Webmaster tools, we can submit and validate our sitemaps, but what about search engines that don't have webmaster tools?
We can't expect search engines to magically know the correct URL to our sitemap, so there is a property in the `robots.txt` file where you can put the URL to your sitemap.
Unfortunately, this property does not support relative URL's, only absolute URL's which means we'll have to generate our `robots.txt` file dynamically as well. We can apply the same technique we used for our sitemap and use the following template.
For a more detailed walkthrough of this, look out for part 2 soon: Crawling through Umbraco with Robots.
Conclusion #
In this post we saw how we can create a Sitemap file that is dynamically generated based on the content in the Umbraco CMS. We leveraged a BasePage composition to filter content down to pages only, and it allowed page by page exclusion from the sitemap.
As I said before, there’s many solutions to solve a given problem. The solution described in this post works well for small to medium size websites, but may fall short for larger sites. Here’s a list of potential improvements that may be required:
- Move query logic to a controller and pass in a dedicated ViewModel to the View catered to the Sitemap structure.
- Cache the Sitemap output
- Pre-generate sitemap periodically and store XML-file on disk
- Split sitemap up into multiple sitemaps to prevent sitemaps from becoming too large
- Generate custom URL’s if you have custom routing where the URL structure doesn’t match 1 on 1 with the Umbraco Content Tree
Hopefully this post helps you with your project, feel free to ask any questions or advice in the comment below!
Source code: You can find the Sitemap code on GitHub
Sources: When going through this exercise for my own work, these sources were very valuable.


