


Create ZIP files on HTTP request without intermediate files using ASP.NET Core MVC, Razor Pages, and endpoints

This article has been updated for .NET 6 on 1/21/2022.
If you're trying to generate ZIPs and send them to the browser using ASP.NET MVC Framework, check out "Create ZIP files on HTTP request without intermediate files using ASP.NET MVC Framework".
.NET has multiple built-in APIs to create ZIP files. The ZipFile class has static methods to create and extract ZIP files without dealing with streams and byte-arrays. ZipFile is a great API for simple use-cases where the source and target are both on disk.
On the other hand, the ZipArchive class uses streams to read and write ZIP files. The latter is more complicated to use but provides more flexibility because you can accept any stream to read from or write to whether the data comes from disk, from an HTTP request, or from a complicated data pipeline.
Using ZipArchive you can create a ZIP file on the fly and send it to the client from ASP.NET without having to save the ZIP file to disk.
In this blog post, you'll learn how to do just that from an ASP.NET (Core) MVC Action, a Razor Page, and a simple endpoint. But first, let's learn how to create the ZIP archive.
You can find all the source code on this GitHub Repository.
Create a ZIP using streams and the ZipArchive class #
For this demo, I have downloaded all the .NET bots from the .NET Brand repository and put them in a folder:
The following code will put all these files into a ZIP archive stored in a MemoryStream:
The code does the following:
- Get all paths to the bot files in the folder using
Directory.GetFilesand store it inbotFilePaths. - You can use any stream which supports synchronous read and write operations, but for this snippet a
MemoryStreamis used which will store the entire ZIP file in memory. This can consume a lot of memory which is why a different stream will be used in later samples.
But for now, create a newMemoryStreamand store it inzipFileMemoryStream. The ZIP archive will be written tozipfileMemoryStream.
You can also use aFileStreaminstead of aMemoryStreamif you want to write the ZIP archive to a file on disk. - Create a new
ZipArchiveand store it inarchive. Instantiate theZipArchivewith the following parameters- stream: pass in
zipFileMemoryStream. TheZipArchivewraps the stream and uses it to read/write. - mode: pass in
ZipArchiveMode.Updateto allow both reading and writing. Other options areReadandCreate - leaveOpen: pass in
trueto leave open the underlying stream after disposing theZipArchive. OtherwisezipfileMemoryStreamwill be disposed whenZipArchiveis disposed which prevents you from interacting with the stream.
- stream: pass in
- For every path in
botFilePaths:- Extract the file name from the bot file path and store it in
botFileName. - Create a
ZipArchiveEntryby callingarchive.CreateEntrypassing in the file name. This entry is where the file data will be stored. - Get a writable
Streamto write to theZipArchiveEntryby callingentry.Open(). - Open a readable
FileStreamto read the bot file by callingSystem.IO.File.OpenReadpassing in the bot file path.
At this point, you don't need to use the full namespace, but it will be required later to avoid collision betweenSystem.IO.Fileand theFilemethod inside of MVC controllers and Razor Pages. - Copy the data from the file stream to the zip entry stream.
- Extract the file name from the bot file path and store it in
- If you now want to read from the memory stream, you have to set the position of the stream back to the beginning. You can do this using
.Seek(0, SeekOrigin.Begin). - Lastly, do whatever you need to do with your in-memory ZIP file.
Warning: Your mileage may vary depending on the size and amount of files you're trying to archive and the amount of resources available on your machine. Saving the ZIP file to disk may be favorable in some scenarios so you can save some rework when the same files are requested again.
If you eventually end up saving or downloading this ZIP archive to disk, it will look like this:
Now that you know how to generate a ZIP file into a stream using ZipArchive and FileStreams, let's take a look at how you can send the stream to the browser in ASP.NET (Core) beginning with MVC.
Create a ZIP file and send it to the browser from an ASP.NET MVC Controller #
Version 1 #
The solution below (first version) stores the entire ZIP file in memory (MemoryStream) before sending the entire file to the client. Feel free to skip to the next section to see the improved version.
The code below shows how you can send the zipFileMemoryStream from the previous code sample to the browser using the File method inherited from the Controller class:
The majority of the code is the same as the prior sample, but there are a couple of changes to take note off:
- The bot files have been stored in a folder in the ASP.NET project called "bots". To get the path to the folder, you first need to get the path to where the project is running.
This path is grabbed from theContentRootPathproperty on theIWebHostEnvironmentclass which is injected through the constructor of theHomeController.
In older versions of .NET Core, you may need to useIHostingEnvironmentinstead ofIWebHostEnvironment. The former has been deprecated since .NET Core 3.0. - The
zipFileMemoryStreamis not in ausingblock anymore. That's because the stream will be returned to the invoker and disposed of later. - The
Filemethod inherited from theControlleris invoked which returns aFileStreamResult. You could create theFileStreamResultyourself, but theFilemethod is provided as a more convenient way to do it.
TheFilemethod uses the following signature with these parameters:- fileStream: Pass in the stream holding the data you want to send to the client which in this case is
zipFileMemoryStream. - contentType: Provide the content-type of the file. Pass in
"application/octet-stream"for binary files or any files you want to force the browser to download instead of display. - fileDownloadName: Tells the browser which file name to use for the downloaded file.
- fileStream: Pass in the stream holding the data you want to send to the client which in this case is
- At the end of the
DownloadBotsaction, theFileStreamResultis returned to MVC and MVC will send the data to the client and dispose of the stream.
The associated view generates the link to the DownloadBots action as follows:
To give this a try, download the sample repository and run it locally. Then, open the browser and browse to 'https://localhost:5001/mvc/home' (change the protocol and port if necessary).
On this page, click on the "Download .NET Bots ZIP with MemoryStream" which will execute the code above, and download the .NET Bots ZIP file.
Version 2: A more memory efficient way
After getting some hints from David Fowler, I found a way to send the file to the client without a MemoryStream. He pointed me towards pipelines which is an interesting API for writing to and reading from pipes at the same time.
You could create a Pipe, get the .Writer, and use the .AsStream() to get a stream to replace the MemoryStream. You could then use the .Reader to read the data as it becomes available and write it to the body.
Or even simpler, you could use HttpContext.Response.BodyWriter. This property is a PipeWriter and when you write to it, it will stream the data to the client.
You can get a Stream from the PipeWriter which you can pass into the ZipArchive.
There are some important differences compared to the previous solution to take note off:
- The return type is an empty
Taskand not anIActionResultbecause theFilemethod andFileStreamResultclass is not being used anymore. Instead of usingFileandFileStreamResult, the data will be written to the body inside the action. - Instead of passing the filename and content-type to the
Filemethod, the headers are set directly on theResponseobject. - Instead of using a
MemoryStream, aStreamrequested usingResponse.BodyWriter.AsStream(). - Instead of using
ZipArchiveMode.Update, you need to useZipArchiveMode.Createbecause you can only write to aPipeWriterStream.
You also don't need to read from the stream anymore since ASP.NET Core will take care of that. - Instead of using
leaveOpen: true, the parameter is omitted and the stream will be disposed of when theZipArchiveis disposed. - The
.SeekandFilemethod are no longer necessary. - The old code has been moved to
DownloadBotsWithMemoryStreamfor side by side comparison.
The associated view generates the link to the DownloadBots action as follows:
To give this a try, download the sample repository and run it locally. Then, open the browser and browse to 'https://localhost:5001/mvc/home' (change the protocol and port if necessary).
On this page, click on the "Download .NET Bots ZIP" which will execute the code above, and download the .NET Bots ZIP file.
Comparing version 1 and 2
The biggest downside of the first version is that the entire ZIP file is being stored in memory as it is generated and then send to the client. As more bot files are stored in the archive, more memory is accumulated.
On the other hand, the second version writes file by file to the BodyWriter and ASP.NET Core takes care of streaming the data to the client. This prevents the data from accumulating in memory.
The difference is huge, especially with lots of large files. The memory graph has been recorded when using lots of large files to make the difference more apparent:
In the graph above, you can see the memory usage plotted over time while executing both version 1 (w MemoryStream) and version 2 (w/o MemoryStream). You may be deceived that there's no increase in memory for version 2, but there actually is.
But the memory fluctuations for version 2 (w/o MemoryStream) are so small in comparison to version 1 that you can't even see it. On the other hand, you can clearly see the accumulation of memory for version 1 (w MemoryStream).
Another interesting difference can be found in the download experience:
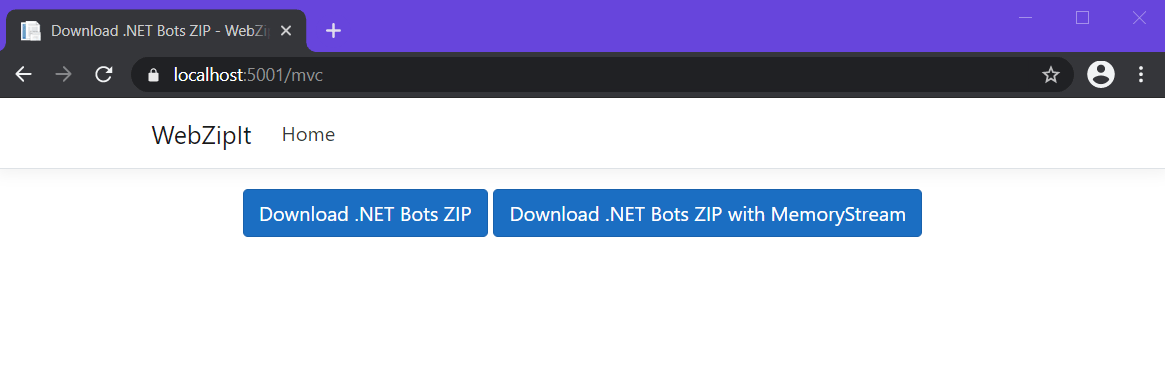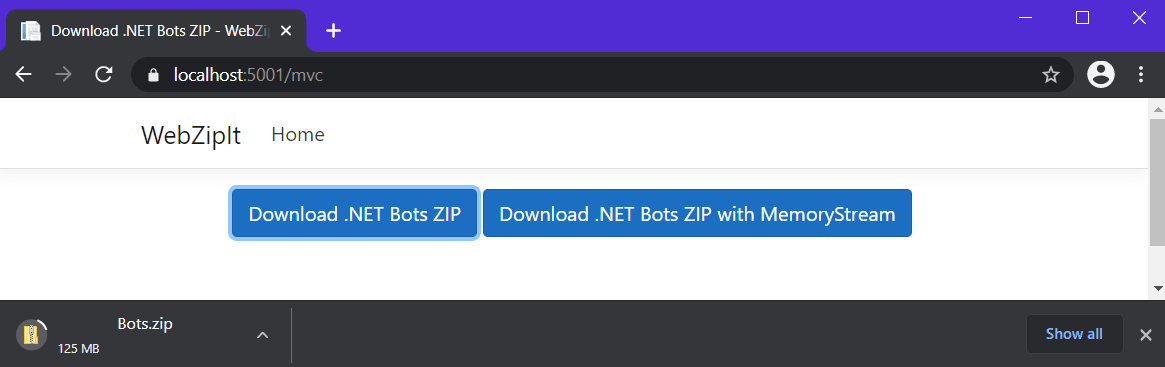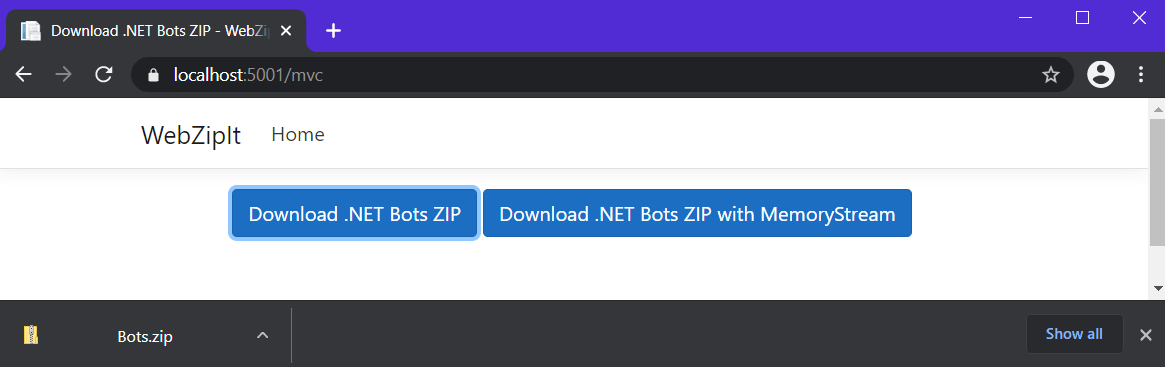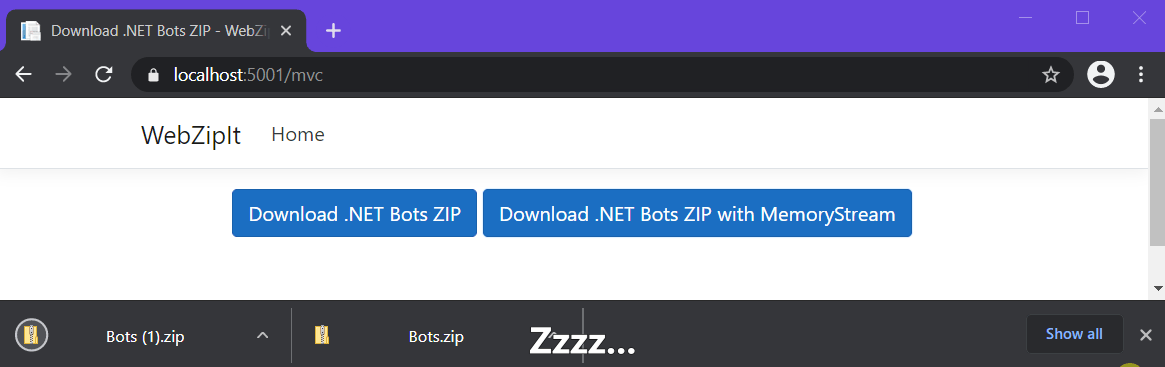
Version 2 (w/o MemoryStream) immediately starts downloading and streams the data as files are added to the ZIP file. On the other hand, you have to wait for a long time for anything to happen with version 1 and then the entire ZIP file is sent all at once.
In the following GIF you can clearly see how more and more data is being sent to the browser every time the data from the file is copied to the ZipArchive at await fileStream.CopyToAsync(entryStream):
Create a ZIP file and send it to the browser from an ASP.NET Razor Page #
The code for sending the ZIP file to the browser using Razor Pages is essentially the same.
The only difference is that you're inheriting from a PageModel instead of a Controller, and you have to follow the naming convention of Razor Pages handler methods which results in the method name OnGetDownloadBots.
Unlike MVC, you need to return an `EmptyResult` even though the response won't be empty. It will still work if you don't, but you will get an error in your logs. The error comes from Razor Pages trying to add some headers after the headers have already been sent to the client in your handler.
In the cshtml-file for this Razor Page, you can see how the asp-page-handler attribute is used to point to OnGetDownloadBots:
To give this a try, download the sample repository and run it locally. Then, open the browser and browse to 'https://localhost:5001/pages' (change the protocol and port if necessary).
On this page, click on the "Download .NET Bots ZIP" which will execute the code above, and download the .NET Bots ZIP file.
Create a ZIP file and send it to the browser from an ASP.NET Endpoint #
If you're not using MVC or Razor Pages, you can use a raw endpoint like this:
To give this a try, download the sample repository and run it locally. Then, open the browser and browse to 'https://localhost:5001/download-bots' (change the protocol and port if necessary).
The above code will be executed and the ZIP file will be downloaded to your machine.
These endpoints work exactly the same when using ASP.NET Core 6's minimal APIs. Here's what that code would look like inside of Program.cs:
You can find the full copy of the .NET 6 version in the "dotNET6" branch of the GitHub repository.
Summary #
The ZipArchive wraps any stream to read, create, and update ZIP archives whether the data is coming from disk, from an HTTP request, from a long data-pipeline, or from anywhere else. This makes ZipArchive very flexible and you can avoid saving a ZIP file to disk as an intermediary step. You can send the resulting stream to the browser using ASP.NET MVC, Razor Pages, and endpoints as demonstrated above.


